
From Alert Overload to Actionable Insight
Can AI-powered triage solve your SAST alert bottleneck? Or will it make a bad situation worse?
We evaluated SAST triage agents, combining real CVEs as true positives with filtered SAST tool findings as false positives to highlight the challenges of automated vulnerability triage in a unique setup that evaluates AI in realistic triage scenarios.
The basis for our research:
- Static Application Security Testing (SAST): SAST tools serve as essential early-warning systems, scanning source code for patterns that indicate potential vulnerabilities. However, their effectiveness faces a persistent challenge as they generate numerous findings where false positives outnumber true risks. Triage, the process of reviewing each alert to determine whether it represents a real security risk or a false alarm, consumes a disproportionate amount of valuable analyst time, creating inefficiency and risk.
- Large language models (LLMs): LLMs offer a promising path to automate this burden. However, meaningful automation requires an AI agent capable of navigating the noisy context of security analysis. While many cybersecurity benchmarks already exist, they do not faithfully model scenarios where organizations might actually deploy AI. We needed a more efficient way to measure an AI agent’s triage capability under realistic conditions.
This led us to develop SASTBench, a new benchmark designed for the special requirements of SAST triage in the real world. SASTBench simulates a real-world production environment, where the agent’s task is to examine each finding and decide whether it represents a real vulnerability.
This blog summarizes the key findings our researchers uncovered. Let’s dive right in.
Building a Real-World Test: The SASTBench Dataset & Experiment
The core of any evaluation is its data.
For SASTBench to have a quantifiable impact, it had to reflect the actual challenge an analyst faces each time an alert is incorrectly marked as “critical” when it is actually benign. We constructed the dataset from several sources to mirror the real data distribution of SAST triage:
- True Positives (The Needles): We used recent Common Vulnerabilities and Exposures (CVEs) affecting open-source projects. These provide concrete, confirmed examples of security flaws that must be caught.
- False Positives (The Haystack): To simulate the overwhelming volumes of noise, we collected a large statistical sample of false positives from real SAST tools on the same open source projects with confirmed recent CVEs.
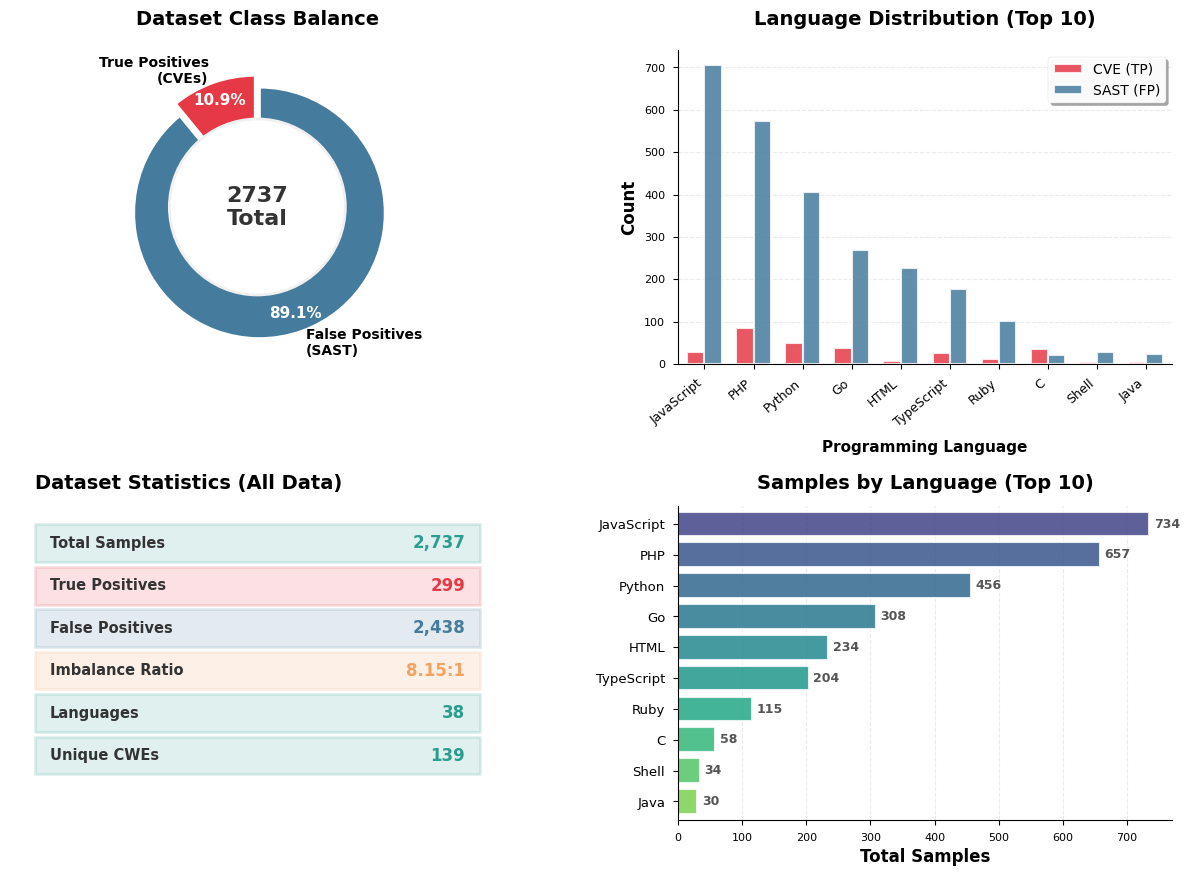
A recent study showed that SAST tools produce 91% noise, flagging code that looks threatening but is not. False positives represent ~89% of the findings in our dataset
For every legitimate vulnerability, an agent must evaluate more than eight false alarms that - while ultimately benign - are indistinguishable from real threats at first glance. This is the frustrating reality of SAST triage.
Each noisy alert increases the overall Total Cost of Ownership (TCO) of SAST tools, as each flagged finding requires additional code reviews, documentation, triage, and approval workflows, leading to friction between engineering and AppSec teams.
Noise is the defining pain point that AI promises to solve. Any test that ignores the difficulty of this noise drastically overestimates an agent’s actual capabilities.
Usually treated as “nice to have”, realistic noise is key - and is baked into SASTBench from the ground up.
Research Insights: Performance, Pitfalls, and the Path Forward
Testing a range of agents on SASTBench yielded interesting, and sometimes counterintuitive, patterns.
Here’s what we found.
The Intuitive - Stronger Models Yield Better Results
We tested a list of seven open- and closed-source models.
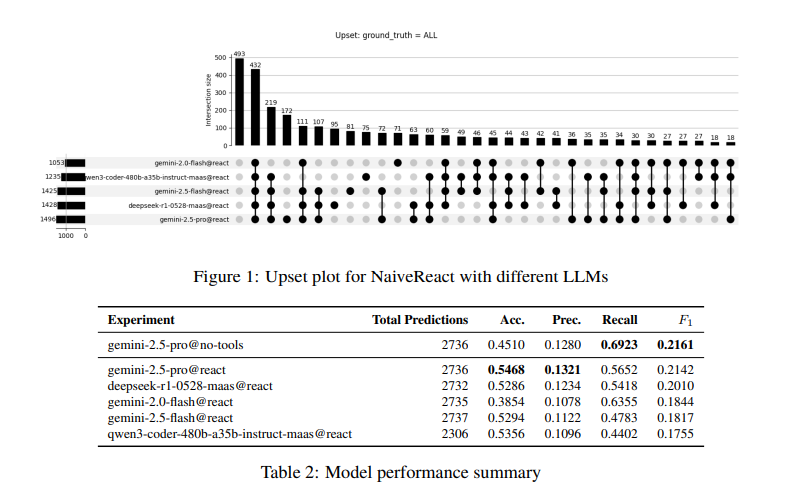
We noticed that the models tend to agree on the prediction in most cases.
Without question, larger and more capable models are better at detecting nuance, which improves performance, resulting in more incremental and meaningful gains.
Our experiments have shown consistent improvement across all metrics with stronger models. This includes Recall (the number of real vulnerabilities we can find) and Precision (fewer false alarms), which typically come at the expense of one another. In other words, the model detects more vulnerabilities while creating fewer false positives. No tradeoff between metrics.
The Power of Specialized Design
Performance can be improved simply by switching to a more powerful base model. The challenge is that after a certain point, you run out of models to benchmark.
We discovered that an even more decisive factor was architecting security expertise into the agent's workflow.
When we engineered a ReAct agent to understand and follow certain “tricks of the trade” ( such as fetching specific code context, analyzing data flow, and assessing exploitability using security-centric reasoning steps), its performance on the benchmark nearly doubled compared to the simple baseline. It is not just about a better LLM - the system built around the model matters significantly, and that an agent’s reasoning must be shaped by domain understanding.
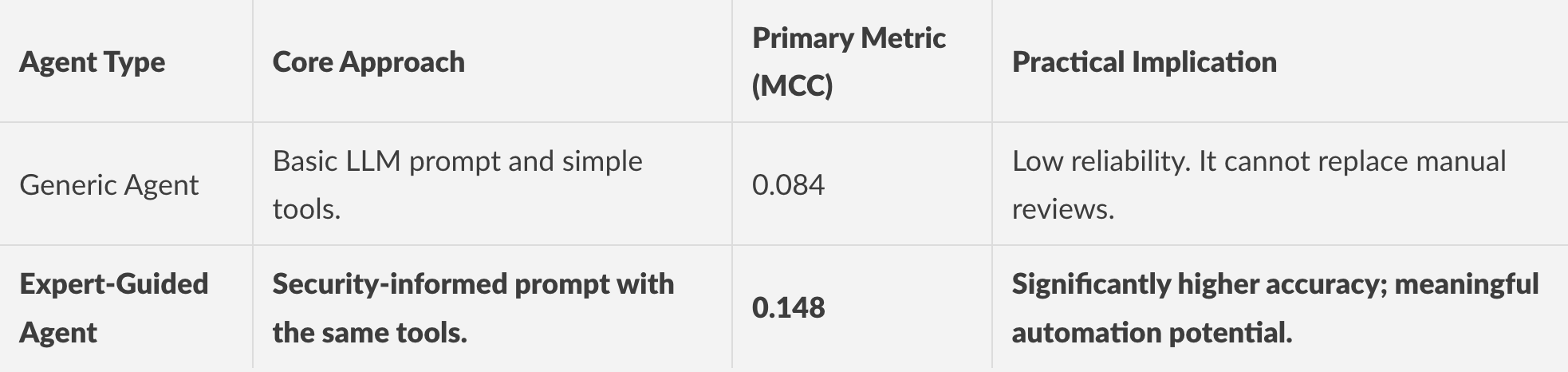
We placed particular emphasis on the Matthews Correlation Coefficient (MCC) as the core evaluation metric for binary classifier performance due to the imbalanced nature of the data.
The required domain expertise is nuanced - we also evaluated generic software engineering agents designed for broad coding tasks, but they failed to consistently or significantly outperform the simple agent.
Lessons Learned from SASTBench
SASTBench provides a principled way to evaluate our agents’ triage capabilities and test our own work.
Based on our experiments, we learned that there is a lot to gain from agent design. Although a model alone is not enough, a slight change, such as a security-oriented prompt, improved a simple agent’s output quite significantly.
We believe this benchmark can benefit security practitioners seeking to optimize agentic workflows for identifying critical vulnerabilities while minimizing alert fatigue caused by high volumes of false positives.
Where do we go from here?
Ultimately, we see SASTBench as a practical tool for understanding and improving the efficiency of automated vulnerability triage; and by extension, helping security teams derive maximum value from each finding.
Curious to see what else we discovered?
The full research paper and key findings can be found here