
TL;DR
As part of Rival Security’s ongoing work to transform cybersecurity through smarter, scalable, and reliable agentic systems, we are excited to share some of the general core concepts behind our reasoning engine - “Conductor”!
A slimmed-down version of our Conductor reasoning core leapfrogs existing scores on solving enterprise-grade reasoning tasks, as interpreted by the Spider2.0 Enterprise Reasoning SQL benchmark:
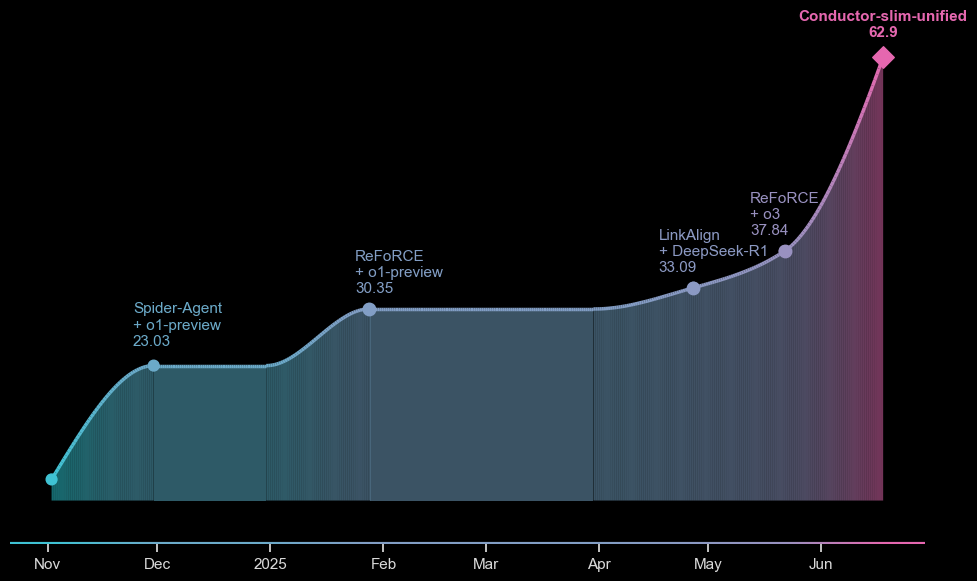
Beyond the high level of performance on the benchmark itself, our unique architecture:
- Allows reasoning to rely on vetted steps for accurate results in cyber-domain specific problems.
- Assists in scalability to a speed and cost appropriate for enterprise-grade use.
- Generates inspectable, verifiable, and correctable artifacts for improved reasoning over time.
While this is not intended to be a pedantic, academic overview of our system, it highlights both the logic behind core concepts in our system as well as how we are going about ensuring its reliability.
The Challenge of Reasoning
Building useful products that rely on LLMs is hindered by a simple fact - today’s agentic approaches excel at toy examples and trivial problems, but their reasoning falls apart at the scale of problems that human reasoning faces in enterprise scenarios.
This “reasoning collapse” is attributable to many inherent attributes of Large Language Models and the engineering frameworks built around them. Some commonly-recognized root causes include:
- Differences between advertised and effective context windows
- Disadvantages of reasoning in discrete token space
- Incorrect generalization from training data to case-specific tasks
- And more!
Engineering around these challenges is an essential component in any AI system. We designed Conductor for this purpose.
Conducting an Orchestra of Steps
We started at a disadvantage - not only do we have to overcome “reasoning collapse”, we have to do it in a way that is trustworthy and can operate at scale. We realized that a fixed agentic design would not answer these criteria.
Taking inspiration from cutting-edge academic approaches, Conductor implements a two-stage process: plan generation and plan orchestration.
Plan Generation
When Conductor is first given the description of an analytical workflow, it breaks down the described problem into discrete logical steps that solve the problem. The operations allowed in each step is definable and extensible by the user - such as SQL queries, python code, free-form agentic reasoning, and so on. This is a similar approach to prompting techniques that have seen efficiency and success in sterile academic environments, such as Plan-and-Solve and Skeleton-of-Thought.
Each logical step is created with well-defined output schemas, as well as inputs that link to the outputs of other steps. Together, this allows Conductor to generate plans with complex interdependencies while still being able to ensure that each individual piece of logic is well-defined.
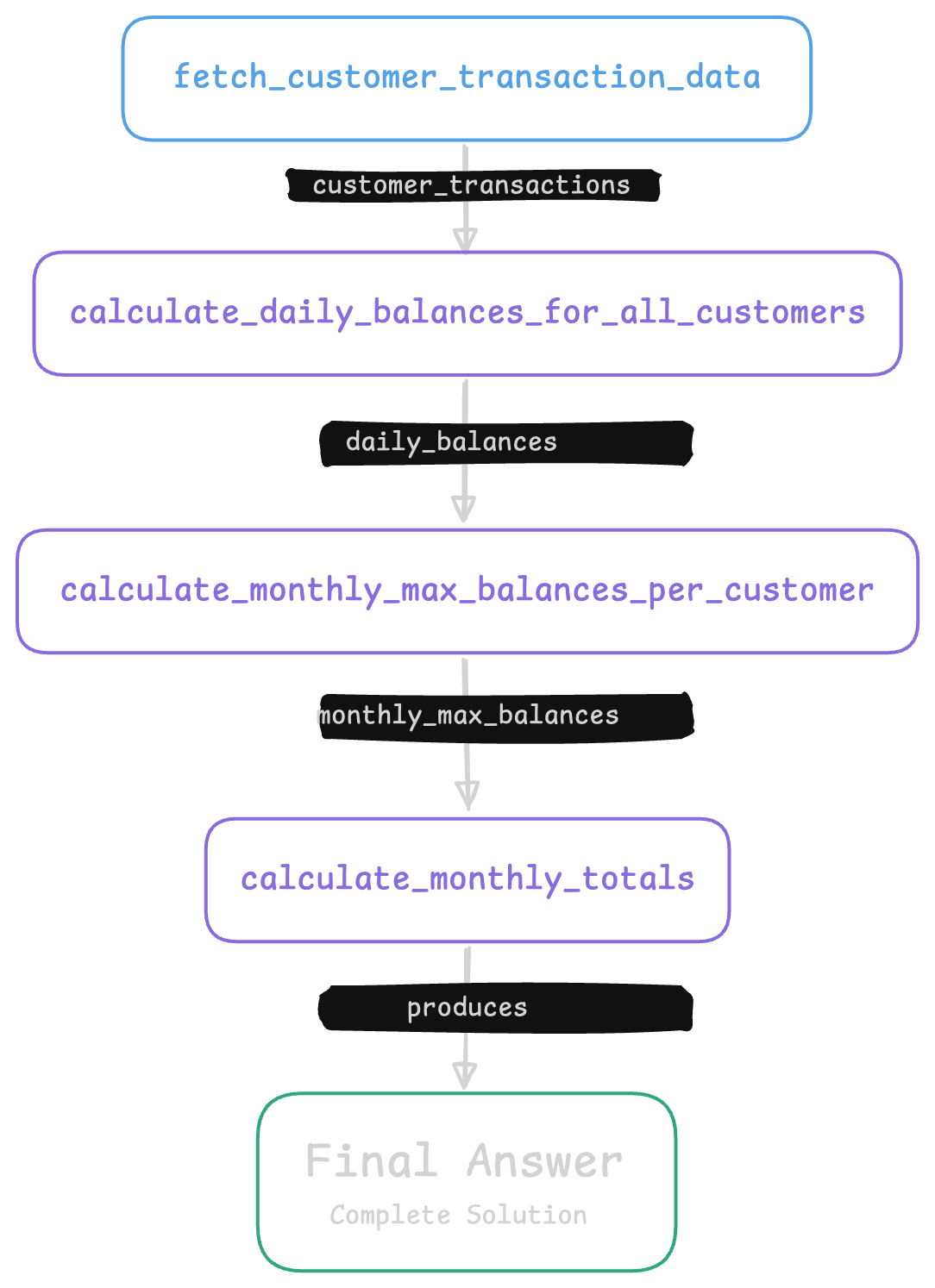
These can be relatively simple - this is the generated flow for reasoning over customer bank data:
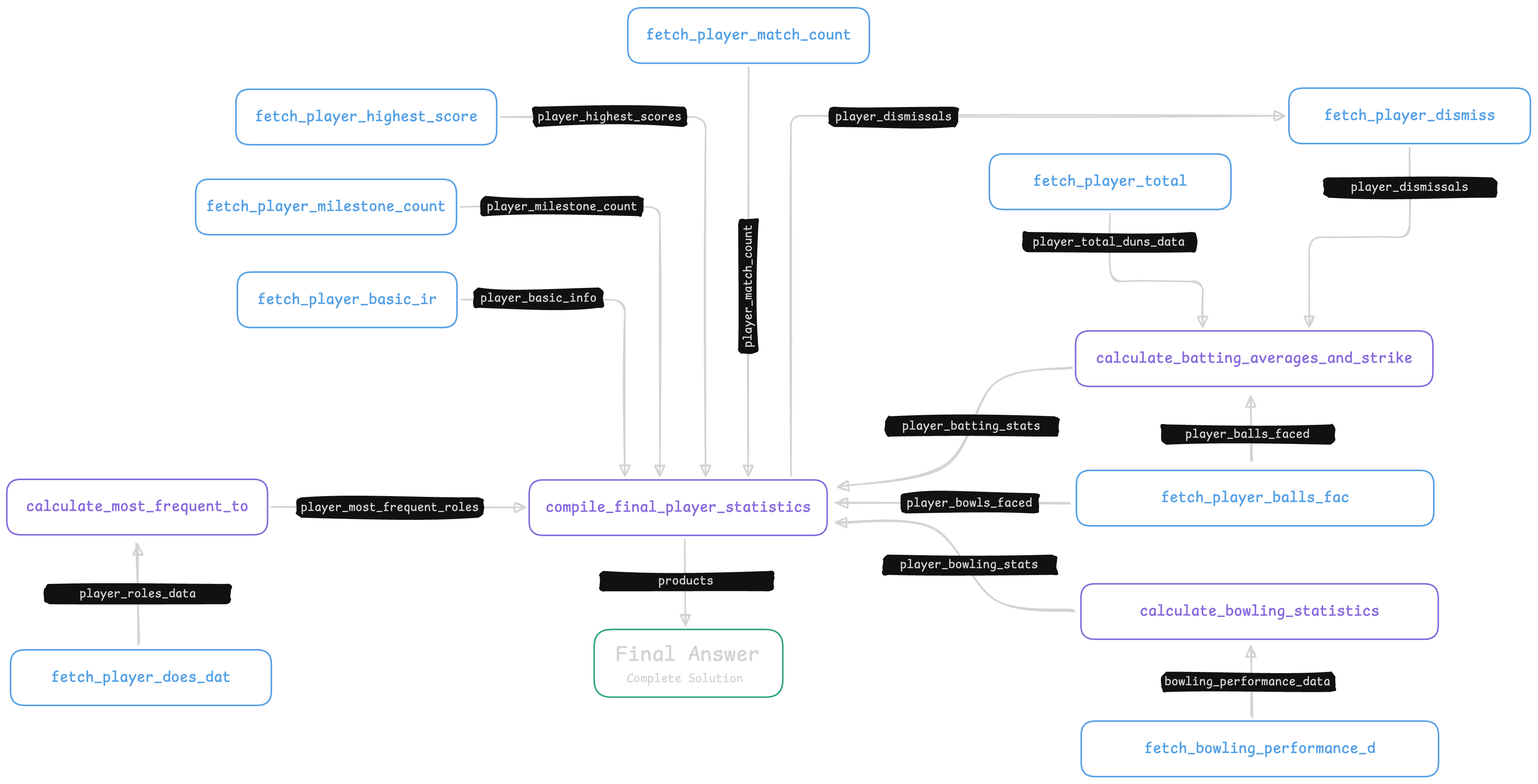
Or they can be quite complicated, such as when asked to summarize complicated aggregation statistics on cricket players:
Plan Composition and Orchestration
Once a plan has been constructed, Conductor has to implement the individual steps.
Each of these steps could be any number of “functions” that have fixed input and output schemas: SQL queries, Python/typescript code, or even on-the-fly subagents!
Large amounts of research has demonstrated the effectiveness of in-context few-shot prompting - where examples of correct behavior are given to the model at generation time. Given that the plan is a DAG, Conductor is able to implement the steps “in order”. Outputs of prerequisite steps are generated and “previewed” to the steps that depend on them, while still enabling full parallelization of independent steps for speed.
Conductor also enforces the output schemas of each step. This acts as another guardrail against insidious logical errors and hallucinations, and empirically serves to “remind” the model of how each individual step’s logic fits into the bigger picture. It has the additional benefit of making it very easy to integrate with existing capabilities that have structured inputs and outputs.
Once orchestration is complete, a complete final answer has been fully assembled. However, assuming that a correct workflow has been composed, the same workflow can be run repeatedly to generate up-to-date answers to the same question, without requiring any additional inference.
Benchmarking Agentic Reasoning
Consider a more general task than cybersecurity - corporate data analysis.
All large companies hold vast datasets and have human analysts responsible for mining that data to extract critical business insights. Translating natural language questions to executable business logic (like SQL) is one of the standard benchmarks to measure the effectiveness of different approaches for logical reasoning over complex data.
The Spider Benchmark and Why It Is Relevant
A standard method to measure this type of reasoning task is the “Spider” family of text-to-sql benchmarks.
On first glance, things look good for LLMs: Spider 1.0’s leaderboard reports that state-of-the-art agents achieve above 90% accuracy in translating natural language analysis questions to verifiable answers backed by SQL!
Things start to fall apart when you examine the details of the benchmark itself, however. The dataset consists of challenging questions such as:
The problem is obvious: Spider 1.0 contains the same kind of trivial, toy examples we just said are irrelevant to real-world use cases.
Spider 2.0 and Cybersecurity Analysis
The folks at Spider realized that too, and set to work creating a new coliseum in which to test the juggernauts of artificial reasoning - Spider 2.0.
Looking at Spider 2.0’s questions, we immediately see that they are significantly harder, and much better represent the kind of real world questions an AI agent would have to reason through. Case in point:
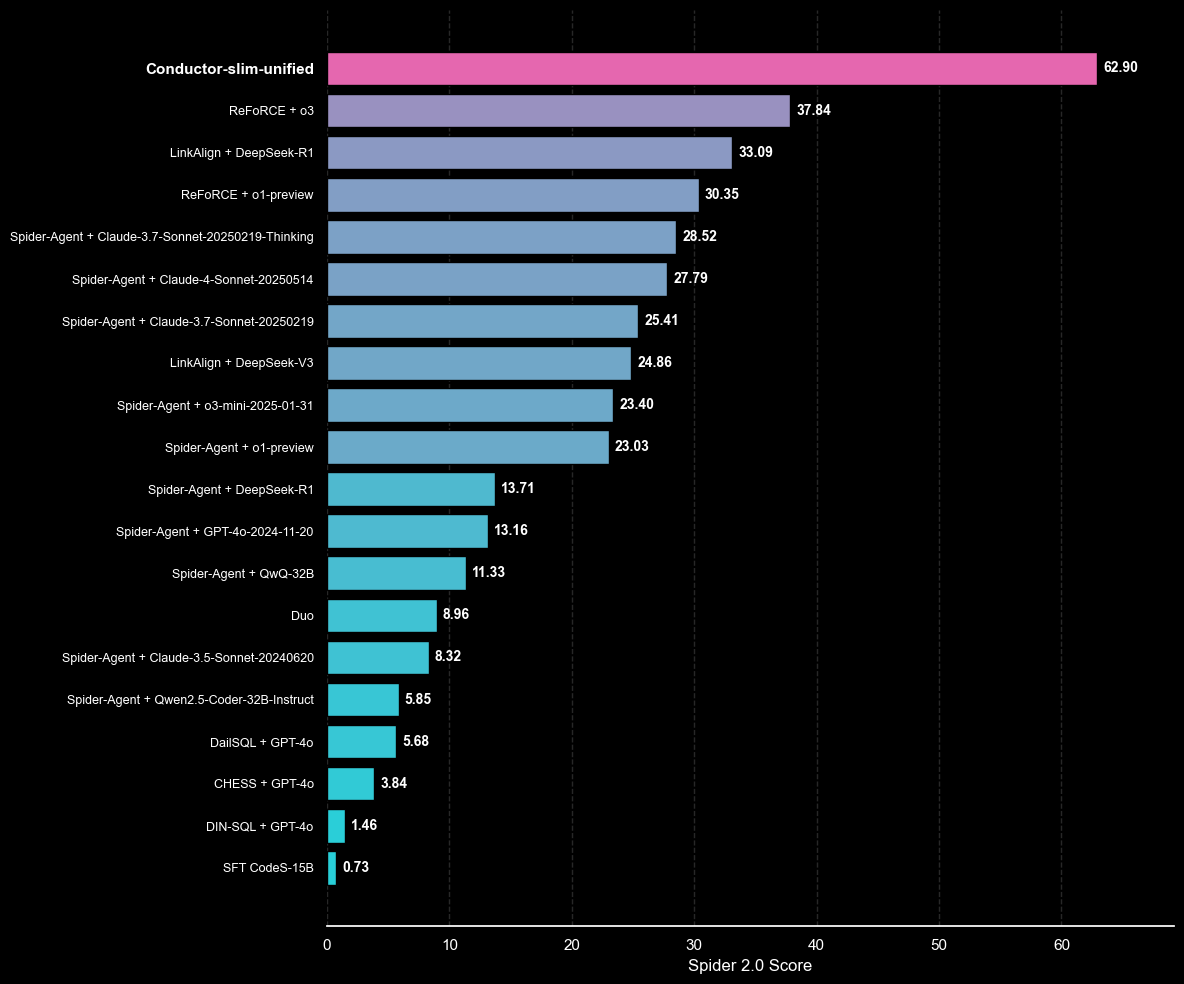
The answer is omitted for brevity – but trust us, it’s complicated. And, what do you know, the numbers go down - hard. Spider 2.0-lite’s leaderboard has the best approach achieving only 37% on these kind of analytical tasks. Approaches that achieved above 80% in Spider 1.0, like DailSQL, achieve only 5.68%!
The specific questions that next-generation cyber platforms need to answer are different than the wide spectrum of subjects in Spider, but their complexity is similar. Take this example adapted from one of our partners.
Clearly this is more similar to Spider 2.0 than Spider 1.0! And herein lies the problem:
A 30% success rate in this case might as well be 0%.
If an agent can’t reliably carry out this task, practitioners cannot and will not use them at all, keeping security teams preoccupied with the copy-and-paste tasks necessary to perform this analysis manually.
Benchmarking Conductor
In order to test the flexibility and power of our approach, we created a slimmed-down version of Conductor’s core logic. We stripped away cybersecurity-specific components, simplified some of the code generation capabilities, and rewrote some of the agent prompts to make more sense in the context of the benchmark.
We then gave this version of Conductor access to the SQLite portion of the Spider 2.0-lite benchmark, and asked Conductor to solve each of the benchmark’s questions.
Given the potential for Conductor to use code as well as SQL queries solve the problem, we would often receive answers that were correct, but with additional information or in a schema that did not match the tabular golden outputs of the benchmark exactly. To properly grade Conductor’s performance, we inspected the outputs for correctness with respect to the benchmark - programmatically, using a critic LLM, and with a final manual pass.
Results
So, how does this match up to the existing Spider 2.0 leaderboard (Taken from here on 19/6/25)?
It almost doubles the existing approaches, successfully answering nearly 63% of the challenge successfully.
Beyond just general improvements, the flexible technology behind Conductor offers significant advantages to domain specific aspects of enterprise cybersecurity challenges:
- Conductor is capable of pulling pre-defined steps from an existing, vetted library into its orchestrated plans, allowing it to be adjusted for performance on domain specific tasks and increasing precision of its results.
- The structured input and output of Conductor’s implemented plans can be run at high scale on new or updated data, with minimal need for additional LLM inference.
- Conductor’s well-structured plans and implementations lend themselves to easy graph-based observability, allowing agentic components (such as prompts) to be adjusted for performance and errors to be easily spotted.
Our Next Steps
Spider 2.0 is an interesting benchmark with high-level relevance to the enterprise reasoning tasks that cyber solutions are required to solve. However, it is clear that production-level systems need to be judged based on their ability to solve cyber tasks specifically.
Existing benchmarks are not up to standard. Some of these are based on curated problem sets (such as XBOW’s recently released validation benchmark based on CTF problems), while others (such as the CASTLE benchmark for vulnerability detection) involve purpose-built examples. No matter the type, they tend to suffer the same issue as Spider 1.0 - overly simple, sterile examples that completely miss the complexity of real-world use cases.
Objective measurements of real-world cybersecurity tasks are of paramount importance, and our research team continues to make strides in this department. We look forward to sharing our approach and results here soon!